
أخبار المنتجات
تحسين تطوير تطبيقات Android بمساعدة الذكاء الاصطناعي وتحسين النماذج اللغوية الكبيرة باستخدام Android Bench
قراءة لمدة دقيقتين


نريد أن نسهّل عليك عملية إنشاء تطبيقات Android عالية الجودة بشكل أسرع، وإحدى الطرق التي نساعدك بها على زيادة إنتاجيتك هي توفير ميزات الذكاء الاصطناعي في متناول يدك. نعلم أنّك تريد ذكاءً اصطناعيًا يفهم بدقة الفروق الدقيقة في نظام Android الأساسي، ولهذا السبب كنّا نقيس أداء النماذج اللغوية الكبيرة في مهام تطوير تطبيقات Android. أطلقنا اليوم الإصدار الأول من Android Bench، وهي قائمة الصدارة الرسمية لنماذج اللغات الكبيرة (LLM) لتطوير تطبيقات Android.
هدفنا هو تزويد صنّاع النماذج بمقياس لتقييم إمكانات النماذج اللغوية الكبيرة في تطوير تطبيقات Android. من خلال وضع أساس واضح وموثوق لما يبدو عليه تطوير تطبيقات Android العالية الجودة، نساعد صنّاع النماذج في تحديد الثغرات وتسريع التحسينات، ما يتيح للمطوّرين العمل بكفاءة أكبر باستخدام مجموعة واسعة من النماذج المفيدة للاختيار من بينها للحصول على المساعدة من الذكاء الاصطناعي، ما سيؤدي في النهاية إلى الحصول على تطبيقات أعلى جودة في جميع أنحاء منظومة Android المتكاملة.
مصمَّمة لتنفيذ مهام تطوير تطبيقات Android في العالم الحقيقي
لقد أنشأنا معيار الأداء من خلال تنظيم مجموعة مهام تتعلّق بمجموعة من مجالات تطوير تطبيقات Android الشائعة. وهي تتألف من تحديات حقيقية بدرجات صعوبة متفاوتة، مصدرها مستودعات Android العامة على GitHub. وتشمل هذه السيناريوهات حلّ التغييرات غير المتوافقة في إصدارات Android المختلفة، والمهام الخاصة بالنطاق، مثل الربط الشبكي على الأجهزة القابلة للارتداء، ونقل البيانات إلى أحدث إصدار من Jetpack Compose، على سبيل المثال لا الحصر.
تحاول كل عملية تقييم أن تجعل نموذج اللغة الكبير يحلّ المشكلة التي تم الإبلاغ عنها في المهمة، ثم نتحقّق من ذلك باستخدام اختبارات الوحدات أو اختبارات الأدوات. يتيح لنا هذا النهج المستقل عن النموذج قياس قدرة النموذج على التنقّل في قواعد الرموز البرمجية المعقّدة وفهم التبعيات وحل المشاكل التي تواجهها كل يوم.
وقد تحقّقنا من صحة هذه المنهجية مع العديد من مطوّري النماذج اللغوية الكبيرة، بما في ذلك JetBrains.
"إنّ قياس تأثير الذكاء الاصطناعي على Android هو تحدٍّ كبير، لذا من الرائع رؤية إطار عمل سليم وواقعي إلى هذا الحد. مع أنّنا نعمل بنشاط على قياس أدائنا، يُعدّ Android Bench إضافة فريدة ومرحب بها. هذه المنهجية هي بالضبط نوع التقييم الصارم الذي يحتاج إليه مطوّرو Android في الوقت الحالي".
- "كيريل سميلوف"، رئيس قسم عمليات دمج الذكاء الاصطناعي في JetBrains
نتائج Android Bench الأولى
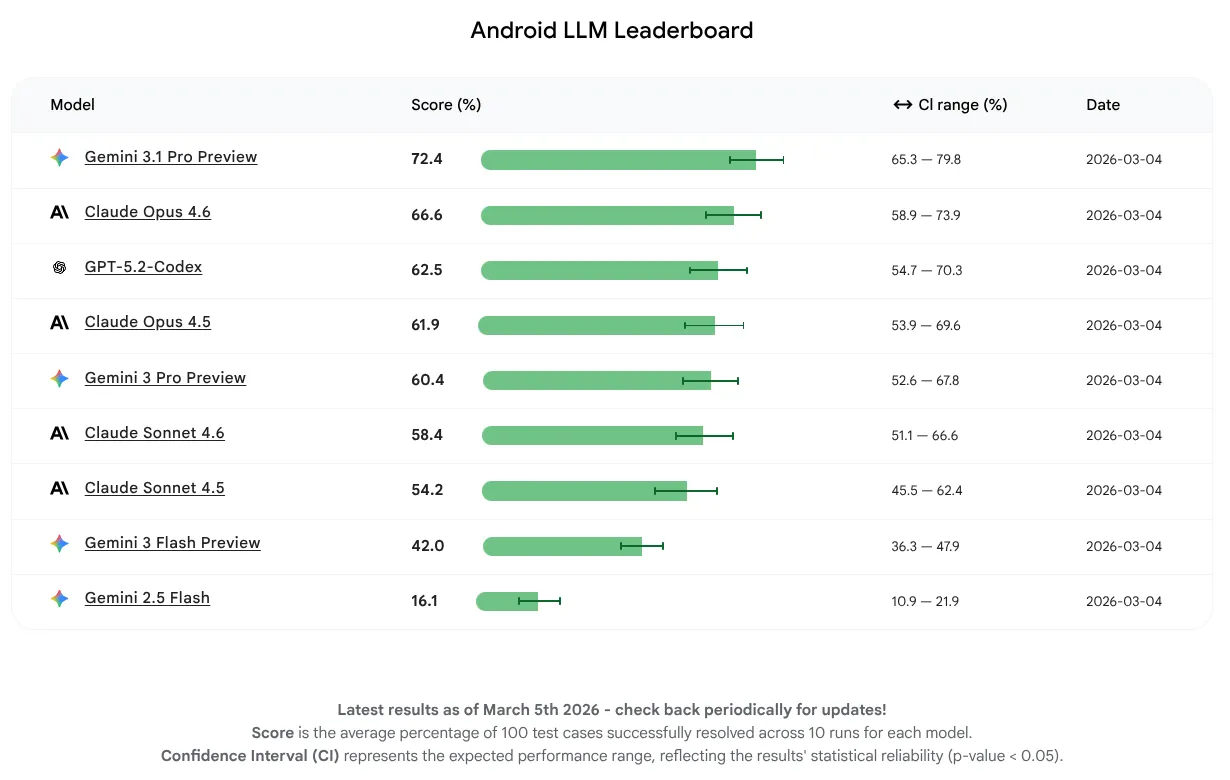
في هذا الإصدار الأوّلي، أردنا قياس أداء النموذج فقط وعدم التركيز على استخدام الأدوات أو الوظائف المستندة إلى الوكلاء. تمكّنت النماذج من إكمال %16 إلى %72 من المهام بنجاح. هذه مجموعة واسعة توضّح أنّ بعض النماذج اللغوية الكبيرة لديها بالفعل أساس قوي لمعرفة Android، بينما لدى البعض الآخر مجال أكبر للتحسين. بغض النظر عن مستوى النماذج حاليًا، نتوقّع تحسّنها باستمرار لأنّنا نشجّع مطوّري النماذج اللغوية الكبيرة على تحسين نماذجهم لتطوير تطبيقات Android.
إنّ نموذج اللغة الكبير الذي حصل على أعلى متوسط نقاط في هذا الإصدار الأول هو Gemini 3.1 Pro، يليه مباشرةً Claude Opus 4.6. يمكنك تجربة جميع النماذج التي قيّمناها للحصول على مساعدة مستندة إلى الذكاء الاصطناعي في مشاريع Android باستخدام مفاتيح واجهة برمجة التطبيقات في أحدث إصدار ثابت من استوديو Android.
توفير الشفافية للمطوّرين وصنّاع النماذج اللغوية الكبيرة
نحن نقدّر النهج المفتوح والشفاف، لذا أتحنا منهجيتنا ومجموعة البيانات وأداة الاختبار للجميع على GitHub.
أحد التحديات التي تواجه أي معيار أداء عام هو خطر تلوّث البيانات، حيث قد تكون النماذج قد اطّلعت على مهام التقييم أثناء عملية التدريب. اتّخذنا إجراءات لضمان أن تعكس نتائجنا استدلالاً حقيقيًا بدلاً من الحفظ أو التخمين، بما في ذلك إجراء مراجعة يدوية شاملة لمسارات الوكيل، أو دمج سلسلة كناري لتثبيط التدريب.
في المستقبل، سنواصل تطوير منهجيتنا للحفاظ على سلامة مجموعة البيانات، مع إجراء تحسينات على الإصدارات المستقبلية من مقياس الأداء، مثل زيادة كمية المهام وتعقيدها.
نتطلّع إلى معرفة كيف يمكن Android Bench أن يحسّن المساعدة المستندة إلى الذكاء الاصطناعي على المدى الطويل. تتمثّل رؤيتنا في سدّ الفجوة بين المفهوم والرمز البرمجي عالي الجودة. نحن بصدد وضع الأساس لمستقبل يمكنك فيه إنشاء أي شيء تتخيله على Android.
تأليف:
متابعة القراءة
-

أخبار المنتجات
نعمل اليوم على تحسين عملية تطوير تطبيقات Android باستخدام Gemma 4، وهو أحدث نموذج مفتوح المصدر ومتطوّر مصمّم بقدرات معقّدة للاستدلال واستخدام الأدوات بشكل مستقل.
Matthew McCullough • مدة القراءة: دقيقتان
-

أخبار المنتجات
أصبح الإصدار التجريبي 3 من Android 17 متوفّرًا اليوم، ما يعني أنّنا حقّقنا ثباتًا في النظام الأساسي. وهذا يعني أنّه تم إيقاف واجهة برمجة التطبيقات، ويمكنك إجراء اختبار التوافق النهائي ونشر تطبيقاتك التي تستهدف الإصدار 17 من نظام التشغيل Android على "متجر Play".
Matthew McCullough • مدة القراءة: 5 دقائق
-
أخبار المنتجات
نطرح اليوم الإصدار التجريبي الثاني من Android 17، ونواصل جهودنا لإنشاء نظام أساسي يمنح الأولوية للخصوصية والأمان والأداء المحسّن.
Matthew McCullough • مدة القراءة: 6 دقائق
البقاء على اطّلاع على آخر التحديثات
يمكنك تلقّي أحدث الإحصاءات حول تطوير تطبيقات Android في بريدك الوارد أسبوعيًا.
