
Una vez que recopiles varios registros con ProfilingManager, explorar cada uno de ellos para encontrar problemas de rendimiento se vuelve poco práctico. El análisis de registros masivo te permite consultar un conjunto de datos de registros de forma simultánea para hacer lo siguiente:
- Identificar regresiones de rendimiento comunes
- Calcula distribuciones estadísticas (por ejemplo, latencia de P50, P90 y P99).
- Encontrar patrones en varios registros
- Encuentra registros atípicos para comprender y depurar los problemas de rendimiento.
En esta sección, se muestra cómo usar el procesador de seguimiento por lotes de Perfetto en Python para analizar las métricas de inicio en un conjunto de registros almacenados de forma local y ubicar los registros atípicos para un análisis más detallado.
Diseña la consulta
El primer paso para realizar un análisis masivo es crear una consulta de PerfettoSQL.
En esta sección, presentamos un ejemplo de consulta que mide la latencia del inicio de la app.
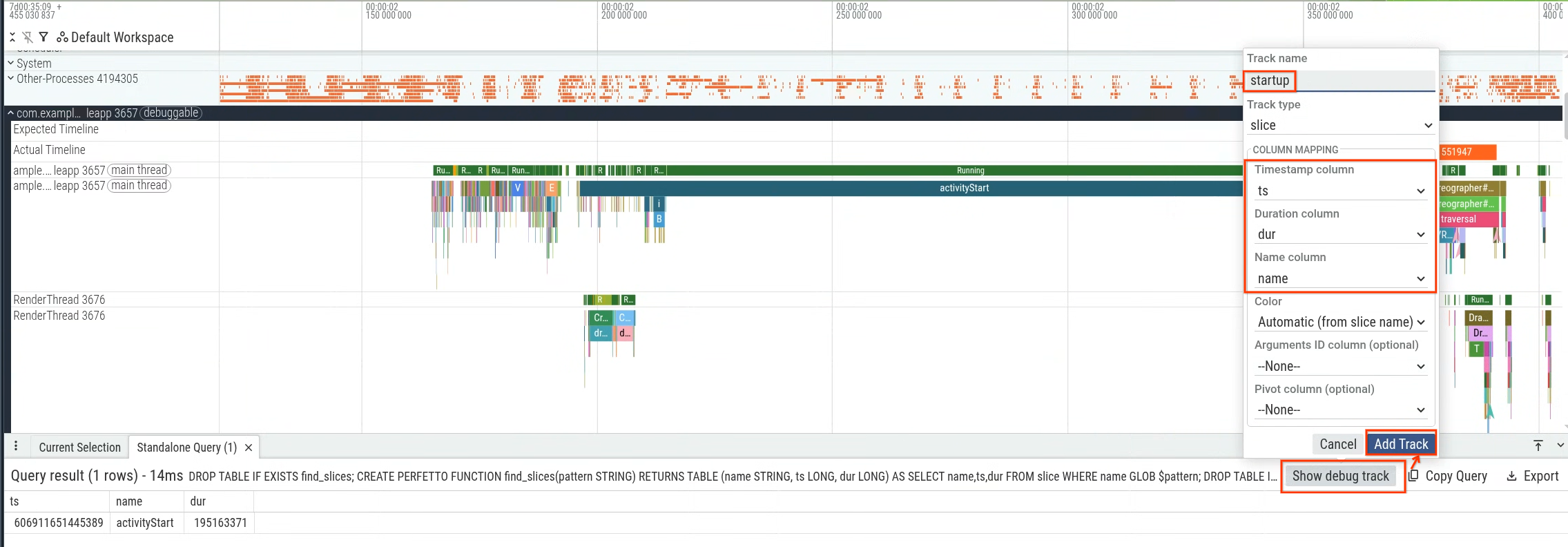
Específicamente, puedes medir la duración desde activityStart hasta el primer fotograma generado (la primera aparición del segmento Choreographer#doFrame) para medir la latencia de inicio de la app que está dentro del control de tu app. En la figura 1, se muestra la sección sobre la que se realizará la consulta.

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
Puedes ejecutar la consulta en la IU de Perfetto y, luego, usar los resultados de la consulta para generar un registro de depuración (figura 2) y visualizarlo en la línea de tiempo (figura 3).

Configura el entorno de Python
Instala Python en tu máquina local y sus bibliotecas requeridas:
pip install perfetto pandas plotly
Crea la secuencia de comandos de análisis de registros masivos
La siguiente secuencia de comandos de muestra ejecuta la consulta en varios registros con BatchTraceProcessor de Perfetto en Python.
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
traces = glob.glob('*.perfetto-trace')
if __name__ == '__main__':
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
Información sobre la secuencia de comandos
Cuando ejecutes la secuencia de comandos de Python, se realizarán las siguientes acciones:
- La secuencia de comandos busca en tu directorio local todos los registros de Perfetto que tengan el sufijo
.perfetto-tracey los usa como registros fuente para el análisis. - Ejecuta una consulta de registro masivo que calcula el subconjunto del tiempo de inicio correspondiente al tiempo desde el segmento de registro
activityStarthasta el primer fotograma generado por tu app. - Traza la latencia en milisegundos con un gráfico de violín para visualizar la distribución de los tiempos de inicio.
Interpretar los resultados
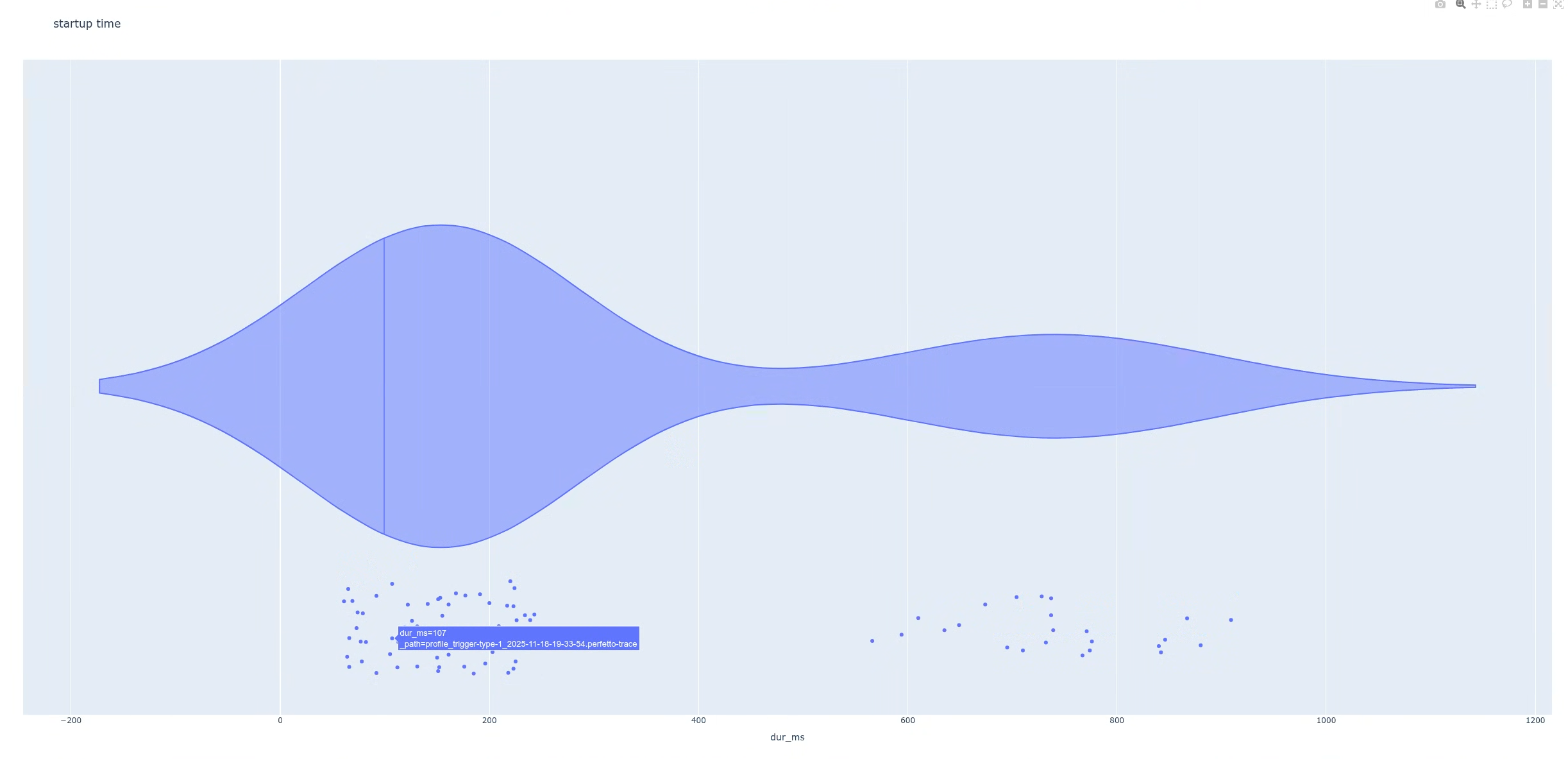
Después de ejecutar la secuencia de comandos, esta generará un gráfico. En este caso, el gráfico muestra una distribución bimodal con dos picos distintos (figura 4).
A continuación, busca la diferencia entre las dos poblaciones. Esto te ayuda a examinar los registros individuales con más detalle. En este ejemplo, el gráfico está configurado de modo que, cuando coloques el cursor sobre los puntos de datos (latencias), puedas identificar los nombres de los archivos de registro. Luego, puedes abrir uno de los registros que forman parte del grupo de latencia alta.
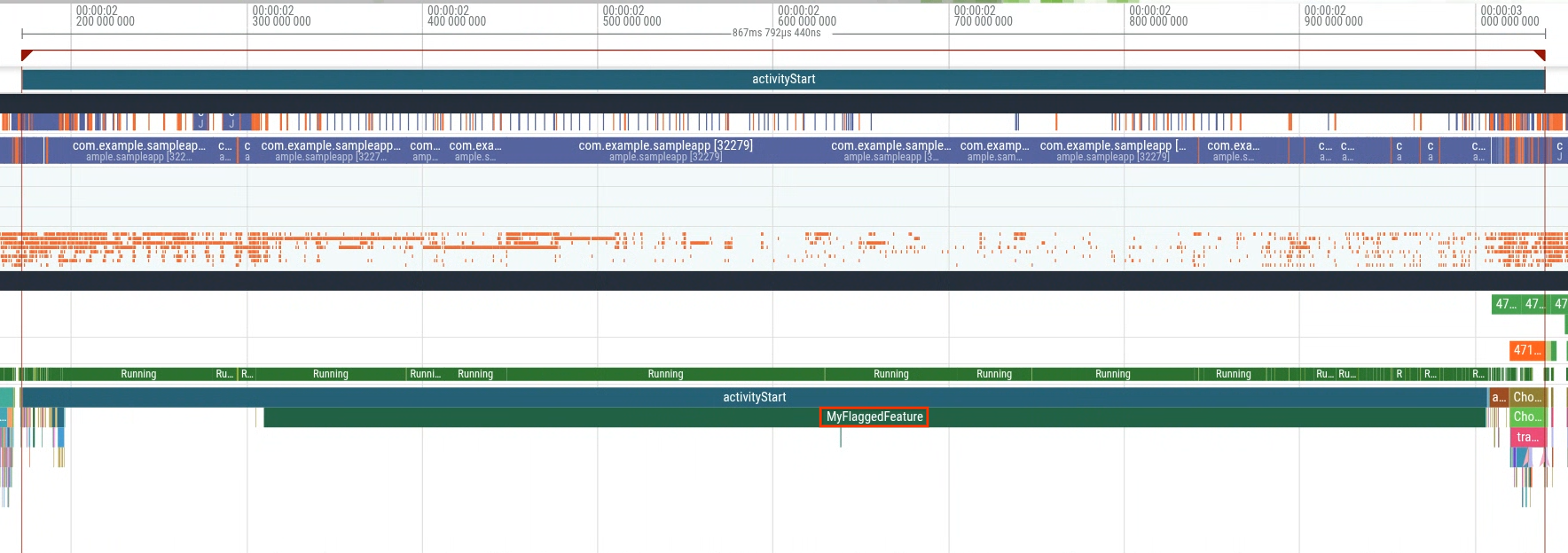
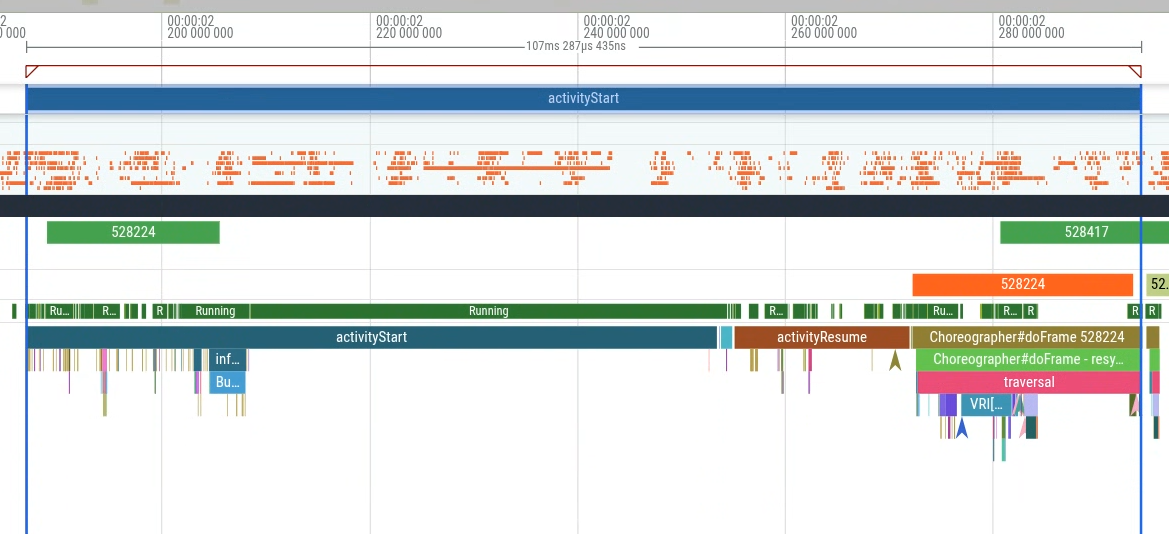
Cuando abras un registro del grupo de latencia alta (figura 5), verás un segmento adicional llamado MyFlaggedFeature que se ejecuta durante el inicio (figura 6).
Por el contrario, seleccionar un registro de la población de latencia más baja (el pico más a la izquierda) confirma la ausencia de ese mismo segmento (figura 7). Esta comparación indica que una marca de función específica, habilitada para un subconjunto de usuarios, activa la regresión.

En este ejemplo, se muestra una de las muchas formas en que puedes usar el análisis de registros masivo. Otros casos de uso incluyen la extracción de estadísticas del campo para medir el impacto, la detección de regresiones y mucho más.