
Os apps que priorizam o modo off-line conseguem executar todos os recursos principais, ou a parte fundamental desses recursos, mesmo sem acesso à Internet. Ou seja, o app pode realizar toda a lógica de negócios, ou parte dela, estando off-line.
As considerações para criar um app que prioriza o modo off-line começam na camada de dados, que oferece acesso aos dados do aplicativo e à lógica de negócios. Periodicamente, o app pode precisar atualizar esses dados usando origens externas ao dispositivo. Para isso, pode ser necessário chamar recursos de rede para atualizar o app.
A disponibilidade de rede nem sempre é garantida. Os dispositivos geralmente têm períodos de conexão de rede lenta ou instável. Os usuários podem estar nestas situações:
- Largura de banda de Internet limitada.
- Interrupções de conexão temporárias, como ao entrar em um elevador ou túnel
- Acesso aos dados ocasional, por exemplo, em tablets que operam somente em rede Wi-Fi.
Independente do motivo, de maneira geral os apps podem funcionar normalmente nessas circunstâncias. Para garantir que seu app funcione corretamente quando estiver off-line, ele precisa:
- Permanecer utilizável quando não houver uma conexão de rede confiável
- Apresentar dados locais imediatamente ao usuário, em vez de esperar que a primeira chamada de rede seja concluída ou falhe
- Buscar dados sem gerar grande impacto no uso da bateria e de dados móveis do usuário. Para isso, o app pode solicitar buscas de dados apenas em condições ideais, como quando o dispositivo está conectado ao carregador ou a uma rede Wi-Fi.
Um app que atende a esses critérios geralmente é chamado de app que prioriza o modo off-line.
Projetar um app que prioriza o modo off-line
Ao projetar um app que prioriza o modo off-line, comece na camada de dados e nas duas principais operações que podem ser realizadas nos dados do app:
- Leitura: acessar dados para uso em outras partes do app, como mostrar informações ao usuário. No Compose, isso geralmente é feito observando o estado. Quando a interface observa a fonte de dados local como estado, a tela reflete automaticamente os dados locais mais recentes.
- Gravação: armazenar entradas do usuário localmente para as extrair mais tarde. No Compose, isso geralmente é feito usando eventos e ações enviados da UI para a ViewModel.
Os repositórios na camada de dados são responsáveis por combinar as fontes de dados para fornecer dados do app. Em um app que prioriza o modo off-line, é necessário existir pelo menos uma fonte de dados que não precise de acesso à rede para realizar as tarefas mais importantes. Uma dessas tarefas importantes é a leitura de dados.
Modelar dados em um app que prioriza o modo off-line
Um app que prioriza o modo off-line tem no mínimo duas fontes de dados para cada repositório que usa recursos de rede:
- A fonte de dados local.
- A fonte de dados de rede.

A fonte de dados local
A fonte de dados local é a fonte de verdade canônica do app e precisa ser a única lida pelas camadas mais altas dele. Isso garante a consistência de dados entre diferentes estados de conexão. A fonte de dados local geralmente tem um backup no armazenamento mantido no disco. Algumas maneiras comuns de manter dados no disco são:
- Em fontes de dados estruturados. Por exemplo: bancos de dados relacionais, como o Room.
- Fontes de dados não estruturados, por exemplo, buffers de protocolo com o DataStore
- Em arquivos simples.
A fonte de dados de rede
A fonte de dados de rede corresponde ao estado real do aplicativo. Na melhor das hipóteses, a fonte de dados
local e a fonte de dados de rede ficam sincronizadas. A fonte de dados local também pode ficar em defasagem em relação à fonte de dados de rede. Nesse caso, o app precisa ser atualizado quando volta a ficar on-line. Por outro lado, a fonte de dados de rede pode ficar em defasagem em relação à fonte de dados local até que o app possa a atualizar quando a conexão for restabelecida. As camadas de domínio e UI do app nunca podem se comunicar diretamente
com a camada de rede. O repository host é o responsável por
se comunicar com ela e usá-la para atualizar a fonte de dados local.
Como expor recursos
A maneira como o app lê e grava dados nas fontes de dados local e de rede pode ser fundamentalmente diferente. A consulta a uma fonte de dados local pode ser rápida e flexível, como ao usar consultas SQL. Por outro lado, as fontes de dados de rede podem ser lentas e restritas, como ao acessar recursos RESTful por ID de forma incremental. Como resultado, geralmente cada fonte precisa da própria representação dos dados fornecidos. As fontes de dados locais e de rede podem ter os próprios modelos.
A estrutura de diretórios a seguir ajuda a visualizar esse conceito. O
AuthorEntity representa um autor lido no banco de dados local do app, enquanto o
NetworkAuthor representa um autor serializado pela rede:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Confira os detalhes de AuthorEntity e NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Recomendamos manter a AuthorEntity e o NetworkAuthor
internos à camada de dados e expor um terceiro tipo de dado para uso pelas camadas
externas. Isso protege as camadas externas contra mudanças mínimas nas fontes de dados local e
de rede que não afetam o comportamento do app.
Essa abordagem é demonstrada no snippet abaixo:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
O modelo de rede pode definir um método de extensão para conversão em modelo local, enquanto o modelo local também define um método para o converter em uma representação externa, conforme mostrado no snippet a seguir:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Leituras
A leitura é uma operação fundamental para os dados em um aplicativo que prioriza o modo off-line. É necessário garantir que o app consiga ler e mostrar novos dados assim que forem disponibilizados. Um app que pode fazer isso é considerado reativo, porque expõe APIs de leitura com tipos observáveis.
No snippet a seguir, o OfflineFirstTopicRepository retorna Flows para
todas as APIs de leitura. Isso permite modificar os leitores ao receber atualizações
da fonte de dados de rede. Em outras palavras, ele permite que o
OfflineFirstTopicRepository envie mudanças quando a fonte de dados local for
invalidada. Cada leitor de OfflineFirstTopicRepository precisa estar
preparado para processar as mudanças de dados que podem ser acionadas ao restaurar a conectividade de rede
no app. Além disso, OfflineFirstTopicRepository lê os dados
diretamente da fonte de dados local. Para notificar os leitores sobre as mudanças
de dados, ele antes precisa atualizar a fonte de dados local.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
Em um app do Jetpack Compose, use um ViewModel para conectar a camada de dados e a UI.
No ViewModel, converta o Flow em um StateFlow usando o operador stateIn. Os combináveis coletam esses estados usando
collectAsStateWithLifecycle() e gerenciam automaticamente as assinaturas de uma
maneira compatível com o ciclo de vida.
Para mais informações sobre collectAsStateWithLifecycle(), consulte
Estado e Jetpack Compose.
Estratégias de tratamento de erros
Existem maneiras específicas de processar erros em apps que priorizam o modo off-line, dependendo das fontes de dados em que o erro ocorrer. As subseções abaixo apresentam essas estratégias.
Fonte de dados local
Tente minimizar os erros ao ler da fonte de dados local. Para proteger
os leitores contra erros, use o operador catch nos respectivos Flows em que
os dados são coletados.
É possível usar o operador catch (link em inglês) em um ViewModel da seguinte forma:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Para uma abordagem mais resiliente, considere uma solução de LCE (erro de carregamento de conteúdo). No LCE, quando há uma falha durante a leitura, você mostra um estado de erro. Normalmente, você consegue o LCE modelando os estados da interface como classes seladas do Kotlin.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Fonte de dados de rede
Se ocorrer um erro durante a leitura de uma fonte de dados de rede, o app vai precisar implementar uma heurística para tentar buscar dados novamente. Heurísticas comuns incluem o seguinte:
Espera exponencial
Na espera exponencial (link em inglês), o aplicativo continua tentando ler a fonte de dados de rede em intervalos cada vez maiores até conseguir realizar a leitura ou até que outras condições façam o app parar.
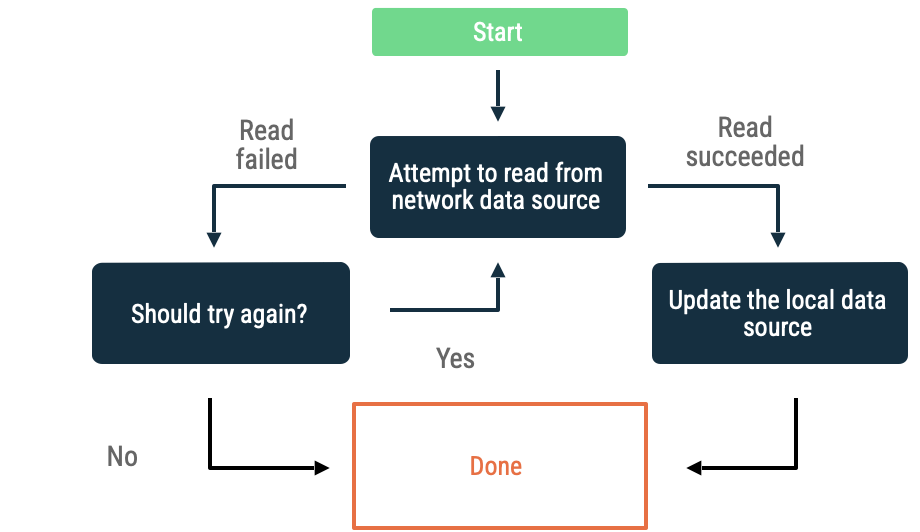
Os critérios para avaliar se o app precisa continuar aguardando incluem:
- O tipo de erro indicado pela fonte de dados de rede. Por exemplo, tente refazer as chamadas de rede quando elas retornarem um erro indicando a falta de conexão. Não tente fazer novas solicitações HTTP não autorizadas até que as credenciais adequadas estejam disponíveis.
- Limite de tentativas permitidas.
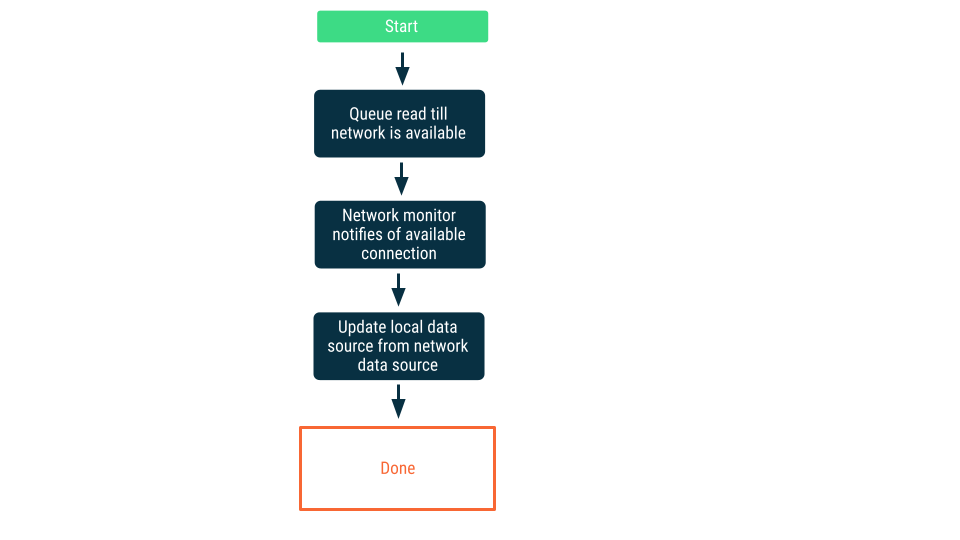
Monitoramento da conectividade de rede
Nessa abordagem, as solicitações de leitura são colocadas em fila até que o app tenha certeza de que pode se conectar à fonte de dados de rede. Depois de estabelecer a conexão, a solicitação de leitura é removida da fila, os dados são lidos e a fonte de dados local é atualizada. No Android, essa fila pode ser mantida usando um banco de dados do Room e pode ser esvaziada com a implementação de trabalho persistente, com o WorkManager.
Gravações
A leitura de dados recomendada para apps que priorizam o modo off-line usa os tipos observáveis. O equivalente disso para APIs de gravação são as APIs assíncronas, por exemplo, funções de suspensão. Isso evita o bloqueio da linha de execução da interface e ajuda no tratamento de erros, já que as gravações em apps que priorizam o modo off-line podem falhar ao cruzar um limite de rede.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
No snippet anterior, a API assíncrona escolhida é a Coroutines, porque o método é de suspensão.
Estratégias de gravação
É importante considerar três estratégias ao gravar dados em apps que priorizam o modo off-line. A escolha vai depender do tipo de dados gravado e dos requisitos do app:
Gravações somente on-line
Tente gravar os dados quando o dispositivo tiver acesso à rede. Se for possível, atualize a fonte de dados local. Caso contrário, gere uma exceção e aguarde o autor da chamada responder da maneira adequada.
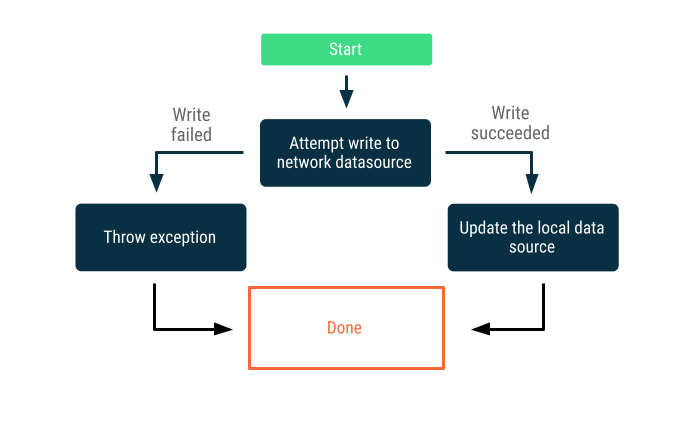
Essa estratégia costuma ser usada para operações de gravação que precisam acontecer on-line quase em tempo real, por exemplo, uma transferência bancária. Como as gravações podem falhar, é necessário informar ao usuário que ocorreu uma falha ou impedir que o usuário tente inserir novos dados. Confira algumas estratégias que você pode usar nesses casos:
- No caso de apps que precisam de acesso à Internet para gravar dados, é possível não mostrar ao usuário uma interface que permite a inserção de dados ou, então, desativar essa interface.
- Use um
AlertDialogque não pode ser dispensado ou umSnackbarpara informar ao usuário que ele está off-line.
Gravações em fila
Coloque em uma fila os objetos que quer gravar. Quando o app
ficar on-line novamente, esvazie a fila com espera exponencial. No
Android, o esvaziamento de uma fila off-line é um trabalho persistente, geralmente delegado ao
WorkManager.

Essa abordagem é uma boa opção nos seguintes cenários:
- Não é essencial que os dados sejam gravados na rede.
- A transação não é urgente.
- Não é essencial informar ao usuário se a operação falhar.
Os casos de uso dessa abordagem incluem geração de registros e eventos de análise.
Gravações lentas
Primeiro, grave na fonte de dados local e, em seguida, coloque a gravação em fila para notificar a rede assim que possível. Esse não é um processo simples, porque pode haver conflitos entre a rede e as fontes de dados locais quando o app volta a ficar on-line. A próxima seção sobre resolução de conflitos apresenta mais informações sobre esse assunto.
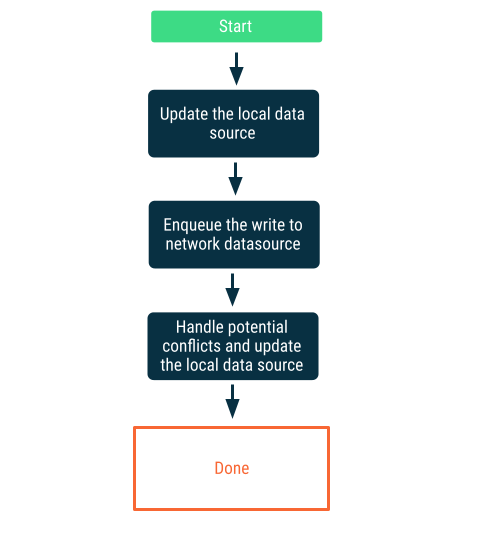
Essa é a escolha certa quando os dados são essenciais para o app. Por exemplo, em um app de lista de tarefas que prioriza o modo off-line, é essencial que as tarefas adicionadas pelo usuário quando o app não está conectado sejam armazenadas localmente para evitar qualquer perda de dados.
Sincronização e resolução de conflitos
Quando um app que prioriza o modo off-line restaura a conectividade, ele precisa reconciliar os dados na fonte de dados local com os da fonte de dados de rede. Esse processo é chamado de sincronização. A sincronização com a fonte de dados de rede pode ser feita de duas maneiras principais:
- Sincronização por extração
- Sincronização por envio
Sincronização por extração
Na sincronização por extração, o app acessa a rede para ler os dados mais recentes de que ele precisa. Uma heurística comum para essa abordagem se baseia na da navegação: o app busca os dados pouco antes de os mostrar ao usuário.
Essa abordagem funciona melhor quando o app consegue prever que vai haver períodos curtos ou intermediários sem conectividade de rede. Isso ocorre porque a atualização de dados depende da possibilidade de conexão. Períodos longos sem conectividade aumentam a chance do usuário tentar acessar destinos do app com caches desatualizados ou vazios.
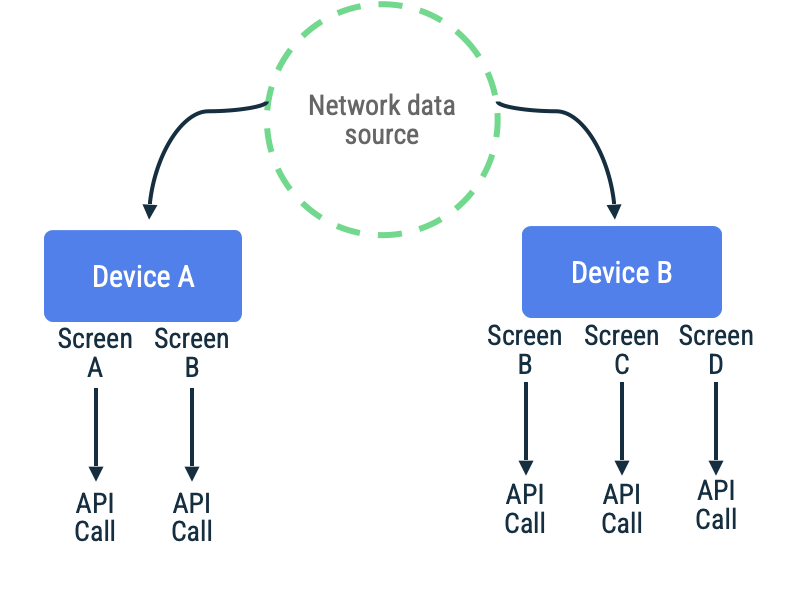
Considere um app em que os tokens de página são usados para buscar itens de uma lista de rolagem
interminável para uma tela específica. Ao implementar essa abordagem, o app pode acessar a rede lentamente,
armazenar os dados na fonte de dados local e, então, ler a fonte de dados local
para mostrar as informações ao usuário. Quando não houver
conectividade de rede, o repositório poderá solicitar dados apenas da
fonte de dados local. Esse é o padrão usado pela
Biblioteca Jetpack Paging com a API RemoteMediator.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
As vantagens e desvantagens da sincronização por extração podem ser conferidas na tabela abaixo:
| Vantagens | Desvantagens |
|---|---|
| Relativamente fácil de implementar. | Costuma usar muitos dados. Isso acontece porque visitas repetidas a um destino de navegação acionam novas buscas desnecessárias de informações que não mudaram. É possível mitigar esse problema com o armazenamento em cache adequado. Isso pode ser feito na camada da UI com o operador cachedIn ou na camada de rede com um cache HTTP. |
| Dados desnecessários nunca são extraídos. | Essa sincronização não funciona bem para dados relacionais, porque o modelo extraído precisa ser autossuficiente. Caso o modelo sincronizado precise buscar outros modelos para ser preenchido, o problema do grande uso de dados mencionado anteriormente vai ser ainda mais grave. Além disso, esse comportamento pode causar dependências entre repositórios do modelo pai e repositórios do modelo aninhado. |
Sincronização por envio
Na sincronização por envio, a fonte de dados local tenta ao máximo imitar um conjunto de réplicas da fonte de dados de rede. Essa sincronização busca ativamente a quantidade necessária de dados na primeira inicialização para definir um valor de referência. Depois disso, ela passa a depender de notificações do servidor que informam quando os dados estão desatualizados.
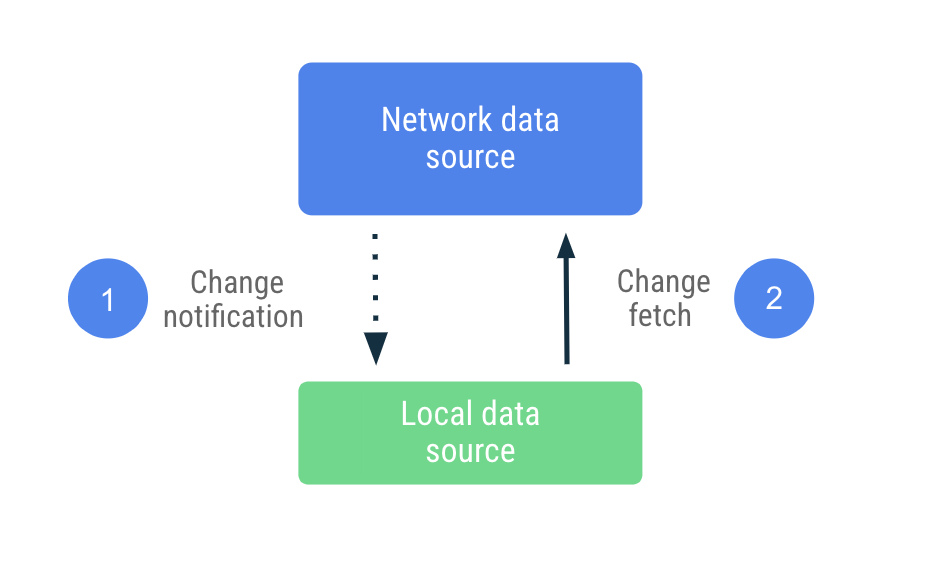
Quando o app recebe a notificação, ele acessa a rede para
atualizar apenas os dados marcados como desatualizados. Esse trabalho é delegado ao
Repository, que acessa a fonte de dados de rede e armazena os dados
extraídos para uso na fonte de dados local. Como o repositório expõe os dados com tipos observáveis, os leitores são notificados quando ocorre qualquer modificação.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Nessa abordagem, o app é muito menos dependente da fonte de dados de rede, podendo funcionar sem ela por longos períodos. Com ela, o app oferece acesso de leitura e gravação mesmo quando está off-line, porque presume que as informações mais recentes da fonte de dados de rede estão armazenadas localmente.
As vantagens e desvantagens da sincronização por envio podem ser conferidas na tabela abaixo:
| Vantagens | Desvantagens |
|---|---|
| O app pode ficar off-line indefinidamente. | O controle de versões de dados para resolução de conflitos é mais complexo. |
| Uso mínimo de dados. O app busca apenas dados que foram modificados. | É necessário considerar as questões relacionadas à gravação durante a sincronização. |
| Funciona bem para dados relacionais. Cada repositório é responsável por buscar dados apenas para o modelo correspondente. | A fonte de dados de rede precisa oferecer suporte à sincronização. |
Sincronização híbrida
Alguns apps usam uma abordagem híbrida e implementam a sincronização por extração ou envio de acordo com o tipo de dado. Por exemplo, um app de rede social pode usar a sincronização por extração para buscar dados relacionados ao feed do usuário quando solicitado, já que o feed é atualizado com muita frequência. Esse mesmo app pode usar a sincronização por envio para atualizar dados sobre a conta conectada, incluindo nome de usuário, foto do perfil, entre outros.
No fim das contas, a escolha de sincronização para um app que prioriza o modo off-line depende dos requisitos do produto e da infraestrutura técnica disponível.
Resolução de conflitos
Se, quando off-line, o app gravar dados localmente que não correspondem à fonte de dados de rede, você precisará resolver o conflito antes que a sincronização possa acontecer.
A resolução de conflitos geralmente exige o controle de versões. O app precisa fazer alguns registros para acompanhar quando as mudanças ocorreram e, assim, transmitir os metadados para a fonte de dados de rede. A fonte de dados de rede é responsável por definir a fonte de verdade absoluta. Existem muitas estratégias que podem ser implementadas para a resolução de conflitos, dependendo das necessidades do aplicativo. No caso de apps para dispositivos móveis, uma abordagem comum é: a gravação mais recente prevalece.
A gravação mais recente prevalece
Nessa abordagem, os dispositivos anexam metadados de carimbo de data/hora aos dados gravados. Quando a fonte de dados de rede recebe esses dados, ela descarta todos os que são anteriores ao estado atual e aceita somente os mais recentes.
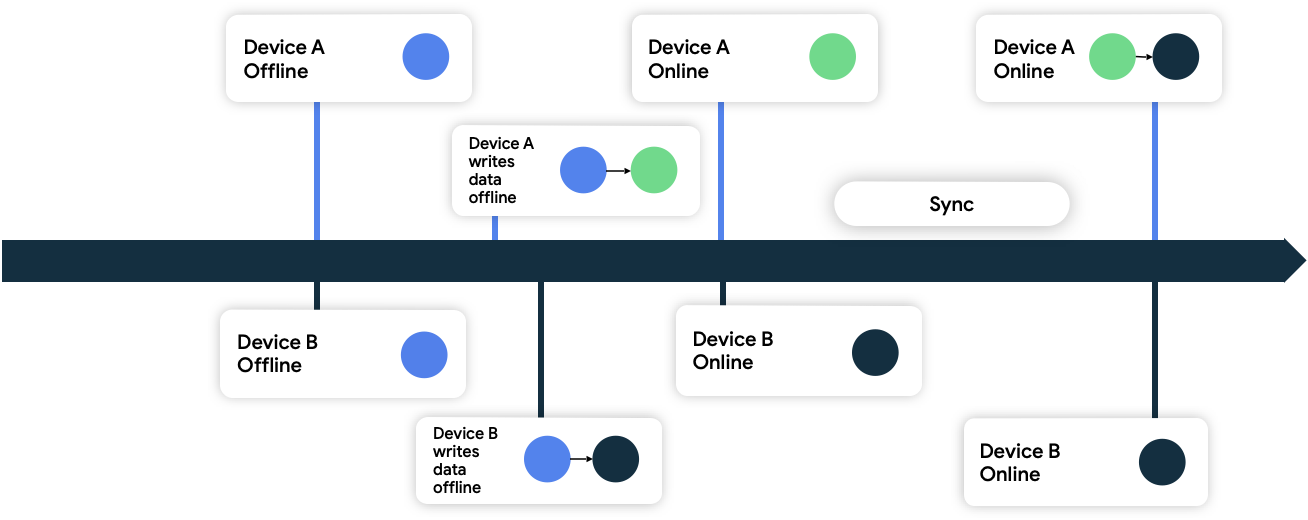
Na Figura 9, os dois dispositivos estão off-line e inicialmente sincronizados com a fonte de dados de rede. Nesse estado, ambos gravam dados localmente e registram o momento de gravação de cada um. Ao ficar on-line e executar a sincronização com a fonte de dados de rede, a rede mantém os dados do dispositivo B para resolver o conflito, porque eles correspondem à gravação mais recente.
WorkManager em apps que priorizam o modo off-line
As estratégias de leitura e gravação apresentadas acima incluem dois utilitários em comum:
- Filas
- Na leitura: usadas para adiar leituras até que a rede esteja disponível.
- Na gravação: usadas para adiar gravações até que a rede esteja disponível e colocar gravações em fila novamente para novas tentativas.
- Monitoramento de conectividade de rede
- Na leitura: usado para sincronização e como sinal para esvaziar a fila de leitura quando o app está conectado.
- Na gravação: usado para sincronização e como sinal para esvaziar a fila de gravação quando o app está conectado.
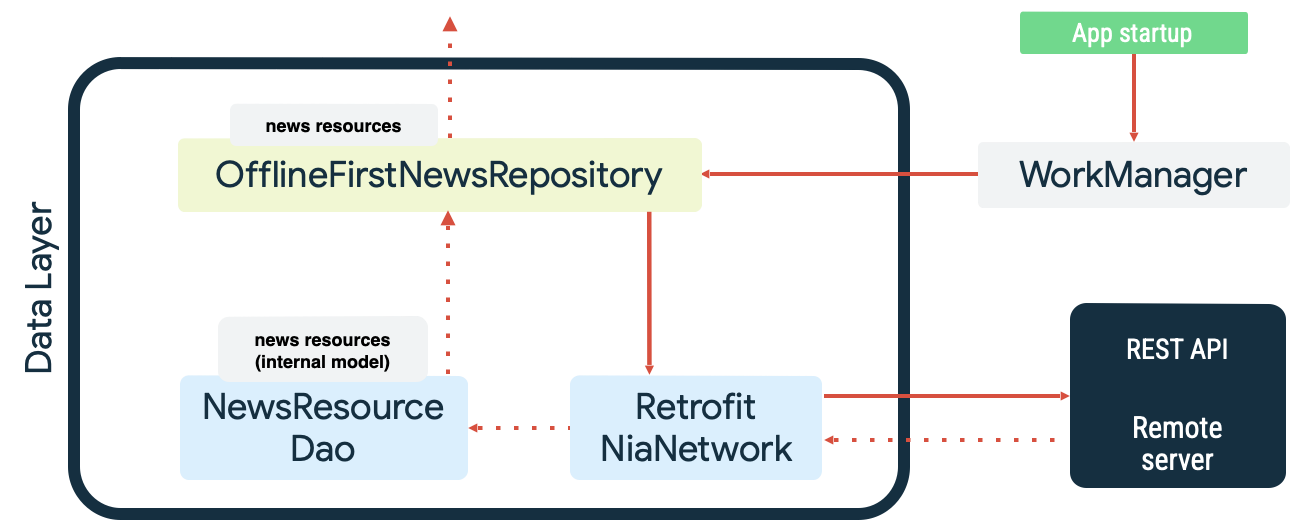
Ambos os casos são exemplos de trabalho persistente que o WorkManager executa muito bem. Por exemplo, no app de exemplo Now in Android (link em inglês), o WorkManager é usado para organizar a fila de leitura e monitorar a rede ao executar a sincronização com a fonte de dados local. Na inicialização, o app faz o seguinte:
- Coloca o trabalho de sincronização de leitura em fila, para garantir que haja paridade entre a fonte de dados local e a de rede.
- Esvazia a fila de sincronização de leitura e inicia a sincronização quando o app fica on-line.
- Realiza uma leitura da fonte de dados de rede usando a espera exponencial.
- Mantém os resultados da leitura na fonte de dados local e resolve qualquer conflito que ocorra.
- Expõe os dados da fonte de dados local para serem usados por outras camadas do app.
Essas ações são ilustradas no diagrama a seguir:
Após o trabalho de sincronização ser colocado em fila pelo WorkManager,
ele é definido como um trabalho específico usando KEEP ExistingWorkPolicy:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() é definido desta forma:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Mais especificamente, as Constraints definidas por SyncConstraints exigem que o
NetworkType seja NetworkType.CONNECTED. Ou seja, ele espera até que a
rede esteja disponível para ser executado.
Quando a rede fica disponível, o Worker esvazia a fila de trabalho
especificada pelo SyncWorkName, delegando os dados às instâncias Repository
adequadas. Quando a sincronização falha, o método doWork() retorna
Result.retry(). Nesse caso, o WorkManager automaticamente tenta realizar a sincronização com
a espera exponencial. Caso contrário, ele retorna Result.success() e conclui a sincronização.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Amostras
Acesse os exemplos do Google abaixo que demonstram apps que priorizam o modo off-line para conferir as orientações na prática:
Recomendados para você
- Observação: o texto do link aparece quando o JavaScript está desativado
- Produção do estado da interface
- Camada de interface
- Camada de dados